
Creazione di pipeline affidabili con le pipeline dichiarative di Lakeflow e Unity Catalog
In Barracuda, il nostro team Enterprise Data Platform si concentra sulla fornitura di pipeline di dati affidabili e di alta qualità che consentono agli analisti e ai leader aziendali di prendere decisioni informate. Per promuovere questa iniziativa, abbiamo adottato Databricks Lakeflow Declarative Pipelines (in precedenza DLT) e Unity Catalog per gestire i nostri flussi di lavoro Extract, Transform, Load (ETL), applicare la qualità dei dati e garantire una governance robusta.
Lakeflow Declarative Pipelines ci ha consentito di sfruttare i dati di utilizzo dei nostri clienti per applicazioni che aiutano i team di rinnovo e successo dei clienti a offrire esperienze migliori. Abbiamo inoltre utilizzato Lakeflow Declarative Pipelines e Unity Catalog per creare dashboard per i nostri team esecutivi, consentendo loro di sfruttare i dati provenienti da più fonti per prendere decisioni finanziarie più informate. Questi casi d'uso si basano su dati altamente disponibili e accurati, per i quali Lakeflow Declarative Pipelines ha fornito un supporto significativo.
Perché le pipeline dichiarative di Lakeflow?
Il framework di trasformazione dichiarativa di base di Databricks, incorporato in Lakeflow Declarative Pipelines, ci consente di definire trasformazioni dei dati e vincoli di qualità. Questo riduce significativamente il sovraccarico operativo nella gestione di processi ETL complessi e migliora l'osservabilità dei nostri flussi di dati. Non dobbiamo più scrivere un codice imperativo per orchestrare le attività; definiamo invece cosa deve fare la pipeline e Lakeflow Declarative Pipelines gestirà tutto il resto. Questo ha reso le nostre pipeline più facili da costruire, comprendere e mantenere.
Dal batch allo streaming
Lakeflow Declarative Pipelines offre funzionalità robuste per semplificare l'elaborazione incrementale dei dati e migliorare l'efficienza nei flussi di lavoro di gestione dei dati. Utilizzando strumenti come Auto Loader, che elabora in modo incrementale i nuovi file di dati man mano che arrivano nel cloud storage, il nostro team di dati può gestire facilmente i dati in entrata. L'inferenza dello schema e i suggerimenti sullo schema semplificano ulteriormente il processo, gestendo l'evoluzione dello schema e garantendo la compatibilità con i set di dati in arrivo.
Ecco come definiamo una tabella di acquisizione in streaming utilizzando Auto Loader. Questo esempio mostra le opzioni di configurazione avanzate per i suggerimenti per gli schemi e le impostazioni di backfill, ma per numerose pipeline, l'inferenza di schema integrata e le impostazioni predefinite sono sufficienti per iniziare rapidamente.

Un'altra potente funzionalità che abbiamo adottato è il supporto di Lakeflow Declarative Pipelines per la CDC (Change Data Capture) automatizzata utilizzando l'istruzione APPLY CHANGES INTO. Per i dati archiviati in sistemi come S3, l'elaborazione incrementale diventa semplice. Questo approccio elimina la complessità della gestione di inserti, aggiornamenti ed eliminazioni. Garantisce inoltre che le nostre tabelle di downstream rimangano sincronizzate con i sistemi di origine, mantenendo al contempo l'accuratezza cronologica se necessario, soprattutto quando si lavora con strumenti come Fivetran che forniscono flussi CDC. Queste funzionalità garantiscono che le pipeline di dati siano non solo accurate e affidabili, ma anche altamente adattabili ad ambienti di dati dinamici.
Di seguito è riportato un esempio di una configurazione SCD1 più avanzata, utilizzando la nostra tabella bronzo come origine, con l'unione degli schemi e il filtraggio personalizzato delle colonne.


Far rispettare la qualità dei dati alle aspettative
Le aspettative relative a Lakeflow Declarative Pipelines ci consentono di testare la qualità dei nostri dati definendo vincoli dichiarativi che convalidano i dati mentre scorrono attraverso la pipeline. Definiamo queste aspettative come espressioni SQL booleane e le applichiamo a ogni set di dati che acquisiamo. Per semplificare la gestione delle regole, abbiamo sviluppato un framework personalizzato che carica le aspettative dai file JSON, facilitando il riutilizzo delle regole tra le pipeline, mantenendo al contempo pulita la base di codice.
Si tratta di un'implementazione avanzata che funziona bene per la nostra scala, ma numerosi team potrebbero iniziare con alcune dichiarazioni in linea ed evolversi poi nel tempo. Di seguito, mostriamo il modo in cui strutturiamo le aspettative JSON e le applichiamo in modo dinamico durante l'esecuzione della pipeline.

Miglioramento delle tabelle di quarantena con UDF
Sebbene Lakeflow metta automaticamente in quarantena i record non validi in base alle aspettative, abbiamo esteso questa funzionalità con un UDF personalizzato per individuare quali regole specifiche ogni record ha violato. Questo approccio aggiunge una colonna "data_quality" alle tabelle in quarantena, semplificando il tracciamento e il debug dei problemi relativi ai dati.
Questa personalizzazione non è necessaria per i flussi di lavoro di quarantena di base, ma offre al nostro team una visibilità più chiara sul motivo per cui i record non riescono e aiuta a stabilire le priorità di riparazione in modo più efficiente. Di seguito è riportato il modo in cui abbiamo implementato questo miglioramento utilizzando le nostre regole di aspettativa predefinite.

Monitoraggio della qualità dei dati e governance con Lakeflow Declarative Pipelines + Unity Catalog
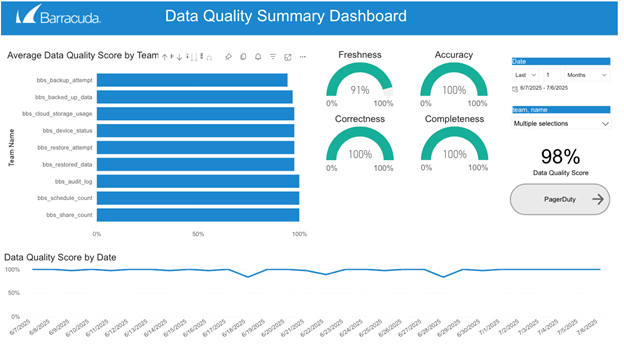
Lakeflow Declarative Pipelines acquisisce automaticamente eventi di runtime dettagliati attraverso il proprio registro eventi integrato, tra cui la convalida delle regole, i record in quarantena e il comportamento di esecuzione della pipeline. Eseguendo query su questo registro, siamo in grado di generare metriche complete sulla qualità dei dati, monitorare lo stato di oltre 100 set di dati e rilevare in modo proattivo i problemi prima che influiscano sugli utenti a valle.
Abbiamo costruito su questa base impostando avvisi in tempo reale che ci avvisano quando i dati non soddisfano le aspettative predefinite o iniziano a deviare dai normali schemi previsti. Questi avvisi consentono al nostro team di investigare rapidamente sulle anomalie e di intraprendere azioni correttive.
Unity Catalog integra tutto questo con governance centralizzata, controllo degli accessi dettagliato e data lineage completo. Questo framework combinato migliora la fiducia nei nostri dati, garantisce l'applicazione coerente delle politiche di qualità e di accesso e ci offre una chiara visibilità sullo stato e sull'evoluzione dei nostri asset di dati.
Lezioni apprese e best practice
L'implementazione di Lakeflow Declarative Pipelines prevede vincoli unici e funzionalità in evoluzione che migliorano l'usabilità per gli sviluppatori e semplificano le operazioni. Inizialmente, limitazioni come il requisito di fonti di sola aggiunta e un unico obiettivo per pipeline rappresentavano delle sfide. Tuttavia, sfruttando funzionalità come i suggerimenti sugli schemi e la capacità di leggere altre tabelle all'interno delle pipeline dichiarative di Lakeflow utilizzando "spark.readTable" ne ha migliorato considerevolmente la flessibilità. Inoltre, abbiamo beneficiato enormemente delle funzionalità di qualità dei dati di Lakeflow Declarative Pipeline. Abbiamo implementato più di 1.000 vincoli sulla qualità dei dati in oltre 100 tabelle. Abbiamo inoltre controlli di qualità dei dati su ogni tabella nell'area di lavoro Databricks. Questo rende il lavoro dei nostri analisti molto più semplice, in quanto sono in grado di trovare, utilizzare, comprendere e fidarsi dei dati nella nostra piattaforma.
Oltre alla qualità e alla governance dei dati, esistono diversi vantaggi a valle misurabili per l'azienda. L'utilizzo di Lakeflow Declarative Pipelines ha comportato notevoli riduzioni nel tempo di sviluppo e una maggiore velocità di consegna, minimizzando al contempo i costi di manutenzione e aumentando l'efficienza del team. Ad esempio, le pipeline costruite con Lakeflow Declarative Pipelines richiedono di solito il 50% in meno di righe di codice rispetto alle pipeline non-Lakeflow Declarative Pipelines, semplificando così sia lo sviluppo sia la manutenzione in corso. Questa efficienza si è tradotta in tempi di avvio della pipeline più rapidi e un supporto più affidabile per le esigenze aziendali in continua evoluzione. Anche l'affidabilità dei dati è migliorata, consentendoci di servire numerosi casi d'uso a valle, come la nostra First Value Dashboard e le Customer Usage Analytics Dashboards, attraverso vari domini aziendali.
L'introduzione dell'IDE di Lakeflow Pipelines, in cui possiamo generare trasformazioni come file SQL e Python e accedere all'anteprima dei dati, alle metriche delle prestazioni della pipeline e al grafico della pipeline (tutto in un'unica visualizzazione), ha ulteriormente aumentato la velocità degli sviluppatori. La migrazione da HMS a Unity Catalog ha ulteriormente perfezionato questo processo, offrendo una migliore visibilità durante l'esecuzione della pipeline. Man mano che Lakeflow Declarative Pipelines si evolve, adottare queste best practice e le lezioni apprese sarà fondamentale per massimizzare sia la qualità dei dati sia l'efficienza operativa in tutta la nostra piattaforma.
Nota: questo post del blog è stato scritto da Sanchitha Sunil e Grizel Lopez.






Iscriviti al blog di Barracuda.
Iscriviti per ricevere i Threat Spotlight, commenti del settore e altro ancora.
